
Home » Chapter 3: Beyond uptime: The real story of continuity
By Cian Fitzpatrick | 13th February 2026
In our last Chapter we saw how Topsec builds a resilient stack infrastructure.
Every email security provider has an uptime figure. And it’s usually displayed prominently to several decimal places. This number serves as a shorthand for reliability and it has a valid role to play. For many decision makers, a high number offers a kind of comfort that the systems their business is run on will stay reliable.
In that sense, uptime is a valuable metric.
It tells you how often a provider keeps its service running without interruption. Yet, as any leader who has lived through a real outage knows, it does not tell the full story.
The day always comes when something unexpected happens. That’s when you get the opposite of uptime. Now you’re in downtime territory.
And it’s at this point that uptime does not measure how a provider responds when systems wobble or when a sudden failure forces everything into unfamiliar territory.
The defining moments in business never arrive with a warning. They appear when a supplier falters or when a region experiences issues. The recent Cloudflare incident is a reminder of how quickly a single disruption can spread. ChatGPT, financial services and major communications platforms were all hit in minutes. Nobody had time to prepare. They simply had to endure the fallout.
This is why only considering a provider’s uptime percentage can be misleading.
Uptime is an important metric, but it looks backward, not forward. It tells you how a system performed in the past. It doesn’t share any insights with you on how it will behave under stress. So when the unexpected happens, the questions for any organisation are far simpler.
Topsec reports 99.999 percent continuity. It is a strong figure by any standard and our whole team works diligently to maintain such a high number.
Yet, there is far more value in the engineering happening in the background that makes this number possible.
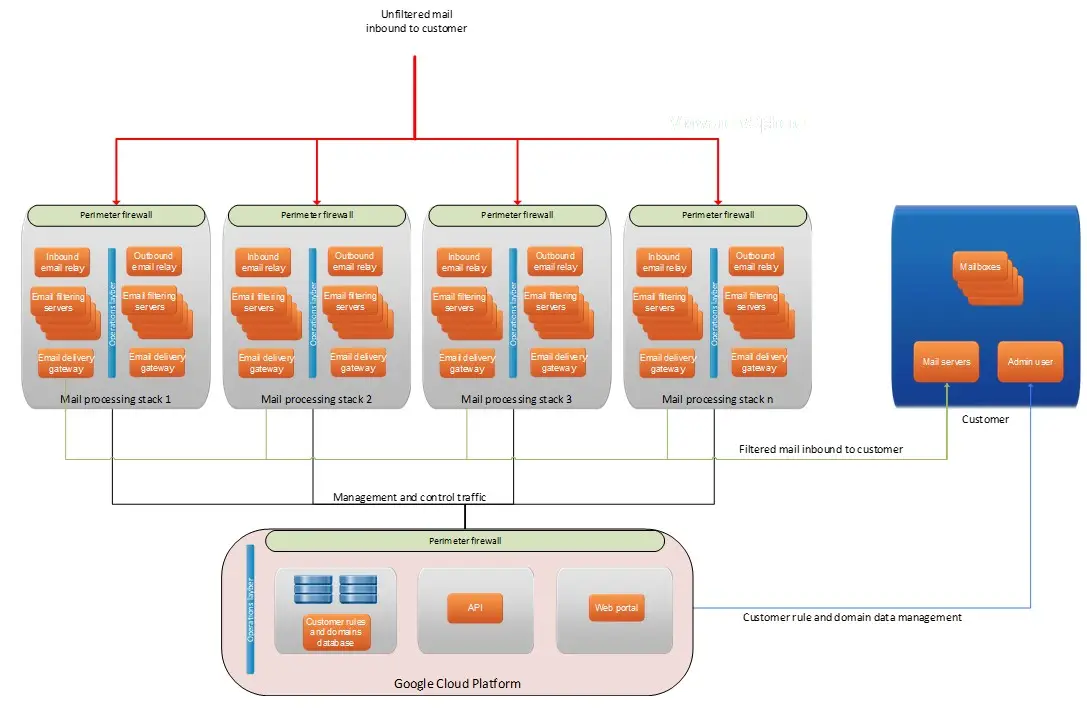
The backbone of the service is a network of independent processing stacks spread across several cities and cloud platforms. Each stack is capable of functioning on its own. If one loses contact with the core system, it does not pause or degrade. It continues scanning, filtering and delivering mail using its own local copy of the rules and data it needs. In theory as well as practice, this means that no single disruption creates a domino effect across the whole system.
The infrastructure is then reinforced by layers that rarely attract attention unless something goes wrong. This includes continuous monitoring that flags unusual behaviour early. Database replicas that stand ready to take over without fuss. Security controls and operational checks that overlap and support one another so that an issue caught in one layer does not climb into the next.
True continuity is about way more than a marketing promise.
It is the result of architectural choices made years before an incident occurs. A provider either plans for disruption or simply hopes to recover when it strikes. It’s clear which approach works better for business continuity.
Hope is not a reliable leadership strategy. They should be able to trust that the systems protecting their communication are already prepared for failure, whether technical or environmental.
Uptime will always appear in conversations about technology. It is an easy benchmark and a necessary one.
However, leaders who want real stability need to ask deeper questions.
What happens if a region goes down? How independent are the environments? How quickly does the system detect unusual behaviour? How much depends on human intervention and how much continues automatically?
In other words, what happens in the minutes that follow an unexpected disruption.
The answers to these questions reveal whether a service is resilient or simply hoping to be.
A high uptime figure is reassuring, but it is only a starting point. It’s not the whole story by any means. Continuity goes much further than a percentage on a page. Fundamentally, it’s the simple expectation that your business communication should keep going even when something completely unexpected happens. It is the work that happens long before anything goes wrong. The planning, the engineering and the quiet decisions that allow a service to stay steady without scrambling for a rescue plan.
When you see a strong uptime figure, look behind it. The real measure of reliability lives in the architecture, the design choices and the quiet systems built to carry the business through the moments that never make it into the reports.
Contact the Topsec team for a no-obligation chat on how we can support your organisation’s business continuity.